
Why Kubernetes For DIGIT
Overview
This page explains why Kubernetes is required. It deep dives into the key benefits of using Kubernetes to run a large containerized platform like DIGIT in production environments.
The Big Why
Kubernetes project started in the year 2014 with more than a decade of experience running production workloads at Google. Kubernetes has now become the de facto standard for deploying containerized applications at scale in private, public and hybrid cloud environments. The largest public cloud platforms AWS, Google Cloud, Azure, IBM Cloud and Oracle Cloud now provide managed services for Kubernetes. A few years back RedHat, Mesosphere, Pivotal, VMware, and Nutanix completely redesigned their implementation with Kubernetes and collaborated with the Kubernetes community to implement the next-generation container platform with incorporated key features of Kubernetes such as container grouping, overlay networking, layer 4 routing, secrets, etc. Today many organizations & technology providers adopting Kubernetes at a rapid phase.
Kubernetes Architecture

One of the fundamental design decisions which have been taken by this impeccable cluster manager is its ability to deploy existing applications that run on VMs without any changes to the application code. On a high level, any application that runs on VMs can be deployed on Kubernetes by simply containerizing its components. This is achieved by its core features; container grouping, container orchestration, overlay networking, container-to-container routing with layer 4 virtual IP-based routing system, service discovery, support for running daemons, deploying stateful application components, and most importantly the ability to extend the container orchestrator for supporting complex orchestration requirements.
On a very high-level Kubernetes provides a set of dynamically scalable hosts for running workloads using containers and uses a set of management hosts called masters for providing an API for managing the entire container infrastructure.
That's just a glimpse of what Kubernetes provides out of the box. The following few sections will go through its core features and explain how it can help applications be deployed on it in no time.
Application Deployment Model

The above figure illustrates the high-level application deployment model on Kubernetes. It uses a resource called ReplicaSet for orchestrating containers. A ReplicaSet can be considered as a YAML or a JSON-based metadata file which defines the container images, ports, the number of replicas, activation health checks, liveness health checks, environment variables, volume mounts, security rules, etc required for creating and managing the containers. Containers are always created on Kubernetes as groups called Pods which is again a Kubernetes metadata definition or a resource. Each pod allows sharing of the file system, network interfaces, operating system users, etc among the containers using Linux namespaces, cgroups, and other kernel features. The ReplicaSets can be managed by another high-level resource called Deployments for providing features for rolling out updates and handling their rollbacks.
A containerized application can be deployed on Kubernetes using a deployment definition by executing a simple CLI command as follows:
Service Discovery & Load Balancing

One of the key features of Kubernetes is its service discovery and internal routing model provided using SkyDNS and layer 4 virtual IP-based routing system. These features provide internal routing for application requests using services. A set of pods created via a replica set can be load balanced using a service within the cluster network. The services get connected to pods using selector labels. Each service will get assigned a unique IP address, a hostname derived from its name and route requests among the pods in a round-robin manner. The services will even provide an IP-hash-based routing mechanism for applications which may require session affinity. A service can define a collection of ports and the properties defined for the given service will apply to all the ports in the same way. Therefore, in a scenario where session affinity is only needed for a given port and where all the other ports are required to use round-robin-based routing, multiple services may need to be used.
How Services Internally Work

Kubernetes services have been implemented using a component called kube-proxy. A kube-proxy instance runs in each node and provides three proxy modes: Userspace, iptables and IPVS. The current default is iptables.
In the first proxy mode: userspace, kube-proxy itself will act as a proxy server and delegate requests accepted by an iptable rule to the backend pods. In this mode, kube-proxy will operate in the userspace and will add an additional hop to the message flow.
In the second proxy mode: iptables, the kube-proxy will create a collection of iptable rules for forwarding incoming requests from the clients directly to the ports of backend pods on the network layer without adding an additional hop in the middle. This proxy mode is much faster than the first mode because of operating in the kernel space and not adding an additional proxy server in the middle.
The third proxy mode was added in Kubernetes v1.8 which is much similar to the second proxy mode and it makes use of an IPVS-based virtual server for routing requests without using iptable rules. IPVS is a transport layer load-balancing feature which is available in the Linux kernel based on Netfilter and provides a collection of load-balancing algorithms. The main reason for using IPVS over iptables is the performance overhead of syncing proxy rules when using iptables. When thousands of services are created, updating iptable rules takes a considerable amount of time compared to a few milliseconds with IPVS. Moreover, IPVS uses a hash table for looking up the proxy rules over sequential scans with iptables. More information on the introduction of IPVS proxy mode can be found in “Scaling Kubernetes to Support 50,000 Services” presentation done by Huawei at KubeCon 2017.
Internal/External Routing Separation

Kubernetes services can be exposed to external networks in two main ways. The first is using node ports by exposing dynamic ports on the nodes that forward traffic to the service ports. The second is using a load balancer configured via an ingress controller which can delegate requests to the services by connecting to the same overlay network. An ingress controller is a background process which may run in a container which listens to the Kubernetes API, and dynamically configure and reloads a given load balancer according to a given set of ingresses. An ingress defines the routing rules based on hostnames and context paths using services.
Once an application is deployed on Kubernetes using kubectl run command, it can be exposed to the external network via a load balancer as follows:
The above command will create a service of load balancer type and map it to the pods using the same selector label created when the pods were created. As a result, depending on how the Kubernetes cluster has been configured a load balancer service on the underlying infrastructure will get created for routing requests for the given pods either via the service or directly.
Usage Of Persistent Volumes

Applications that require persisting data on the filesystem may use volumes for mounting storage devices to ephemeral containers similar to how volumes are used with VMs. Kubernetes has properly designed this concept by loosely coupling physical storage devices with containers by introducing an intermediate resource called persistent volume claims (PVCs). A PVC defines the disk size, and disk type (ReadWriteOnce, ReadOnlyMany, ReadWriteMany) and dynamically links a storage device to a volume defined against a pod. The binding process can either be done in a static way using PVs or dynamically by using a persistent storage provider. In both approaches, a volume will get linked to a PV one-to-one and depending on the configuration given data will be preserved even if the pods get terminated. According to the disk type used multiple pods will be able to connect to the same disk and read/write.
Disks that support ReadWriteOnce will only be able to connect to a single pod and will not be able to share among multiple pods at the same time. However, disks that support ReadOnlyMany will be able to share among multiple pods at the same time in read-only mode. In contrast, as the name implies disks with ReadWriteMany support can be connected to multiple pods for sharing data in read-and-write mode. Kubernetes provides a collection of volume plugins for supporting storage services available on public cloud platforms such as AWS EBS, GCE Persistent Disk, Azure File, Azure Disk and many other well-known storage systems such as NFS, Glusterfs, iSCSI, Cinder, etc.
Deploying Daemons On Nodes

Kubernetes provides a resource called DaemonSets for running a copy of a pod in each Kubernetes node as a daemon. Some of the use cases of DaemonSets are as follows:
Deploy the cluster storage daemon such as
glusterd,cephon each node to provide persistence storage.Run the node monitoring daemon such as Prometheus Node Exporter on every node to monitor the container hosts.
Run the log collection daemon such as
fluentdorlogstashon every node for collecting container and Kubernetes component logs.Run the ingress controller pod on a collection of nodes for providing external routing.
Deploying Stateful Distributed Systems

One of the most difficult tasks of containerizing applications is the process of designing the deployment architecture of stateful distributed components. Stateless components can be easily containerized as they may not have a predefined startup sequence, clustering requirements, point-to-point TCP connections, unique network identifiers, graceful startup and termination requirements, etc. Systems such as databases, big data analysis systems, distributed key/value stores, and message brokers, may have complex distributed architectures that may require the above features. Kubernetes introduced StatefulSets resource for supporting such complex requirements.
On high-level StatefulSets are similar to ReplicaSets except that it provides the ability to handle the startup sequence of pods, and uniquely identify each pod for preserving its state while providing the following characteristics:
Stable, unique network identifiers.
Stable, persistent storage.
Ordered, graceful deployment and scaling.
Ordered, graceful deletion and termination.
Ordered, automated rolling updates
In the above, stable refers to preserving the network identifiers and persistent storage across pod rescheduling. Unique network identifiers are provided by using headless services as shown in the above figure. Kubernetes has provided examples of StatefulSets for deploying Cassandra, and Zookeeper in a distributed manner.
Running Background Jobs
In addition to ReplicaSets and StatefulSets Kubernetes provides two additional controllers for running workloads in the background called Jobs and CronJobs. The difference between Jobs and CronJobs is that Jobs executes once and terminates whereas CronJobs get executed periodically by a given time interval similar to standard Linux cron jobs.
Deploying Databases
Deploying databases on container platforms for production usage would be a slightly more difficult task than deploying applications due to their requirements for clustering, point-to-point connections, replication, shading, managing backups, etc. As mentioned previously StatefulSets has been designed specifically for supporting such complex requirements and there are a couple of options for running PostgreSQL, and MongoDB clusters on Kubernetes today. YouTube’s database clustering system Vitess which is now a CNCF project would be a great option for running MySQL at scale on Kubernetes with shading. By saying that it would be better to note that those options are still in very early stages and if an existing production-grade database system is available on the given infrastructure such as RDS on AWS, Cloud SQL on GCP, or on-premise database cluster it might be better to choose one of those options considering the installation complexity and maintenance overhead.
Configurations Management
Containers generally use environment variables for parameterizing their runtime configurations. However, typical enterprise applications use a considerable amount of configuration files for providing static configurations required for a given deployment. Kubernetes provides a fabulous way of managing such configuration files using a simple resource called ConfigMaps without bundling them into container images. ConfigMaps can be created using directories, files or literal values using the following CLI command:
Once a ConfigMap is created, it can be mounted to a pod using a volume mount. With this loosely coupled architecture, configurations of an already running system can be updated seamlessly just by updating the relevant ConfigMap and executing a rolling update process which I will explain in one of the next sections. It might be important to note that currently, ConfigMaps does not support nested folders, therefore if there are configuration files available in a nested directory structure of the application, a ConfigMap would need to be created for each directory level.
Credentials Management
Similar to ConfigMaps Kubernetes provides another valuable resource called Secrets for managing sensitive information such as passwords, OAuth tokens, and ssh keys. Otherwise updating that information on an already running system might require rebuilding the container images.
A secret can be created for managing basic auth credentials using the following way:
Once a secret is created, it can be read by a pod either using environment variables or volume mounts. Similarly, any other type of sensitive information can be injected into pods using the same approach.
Rolling Out Updates
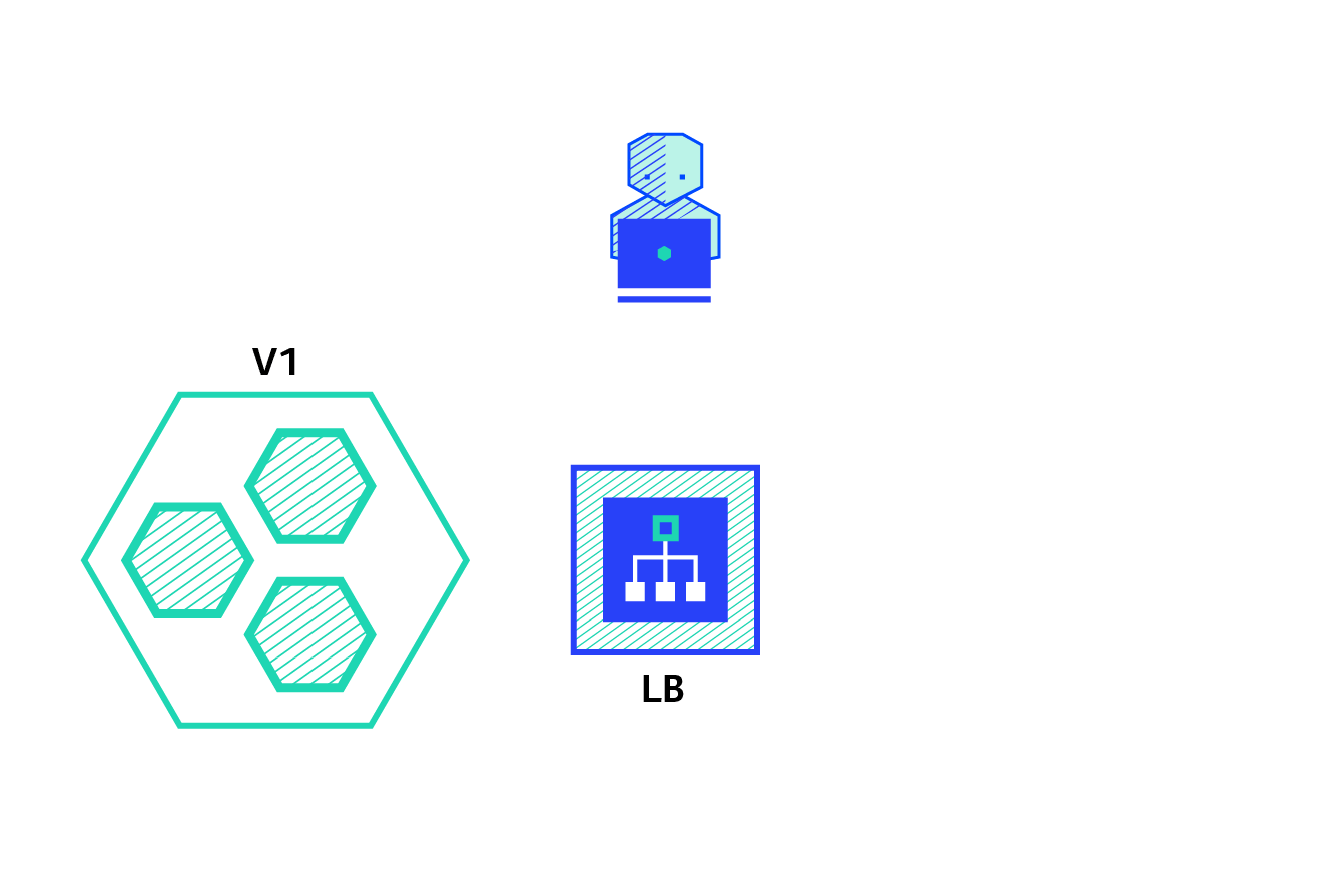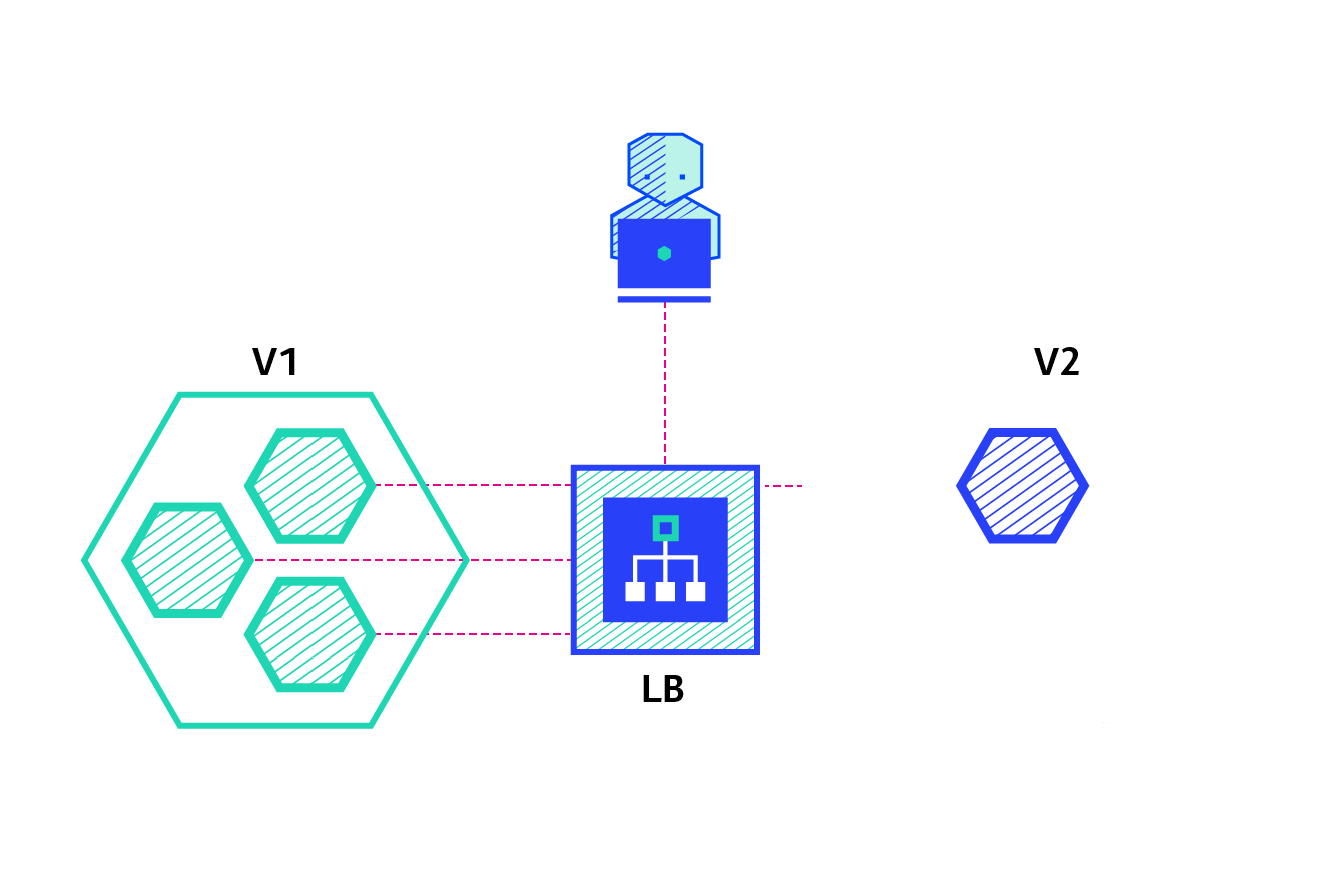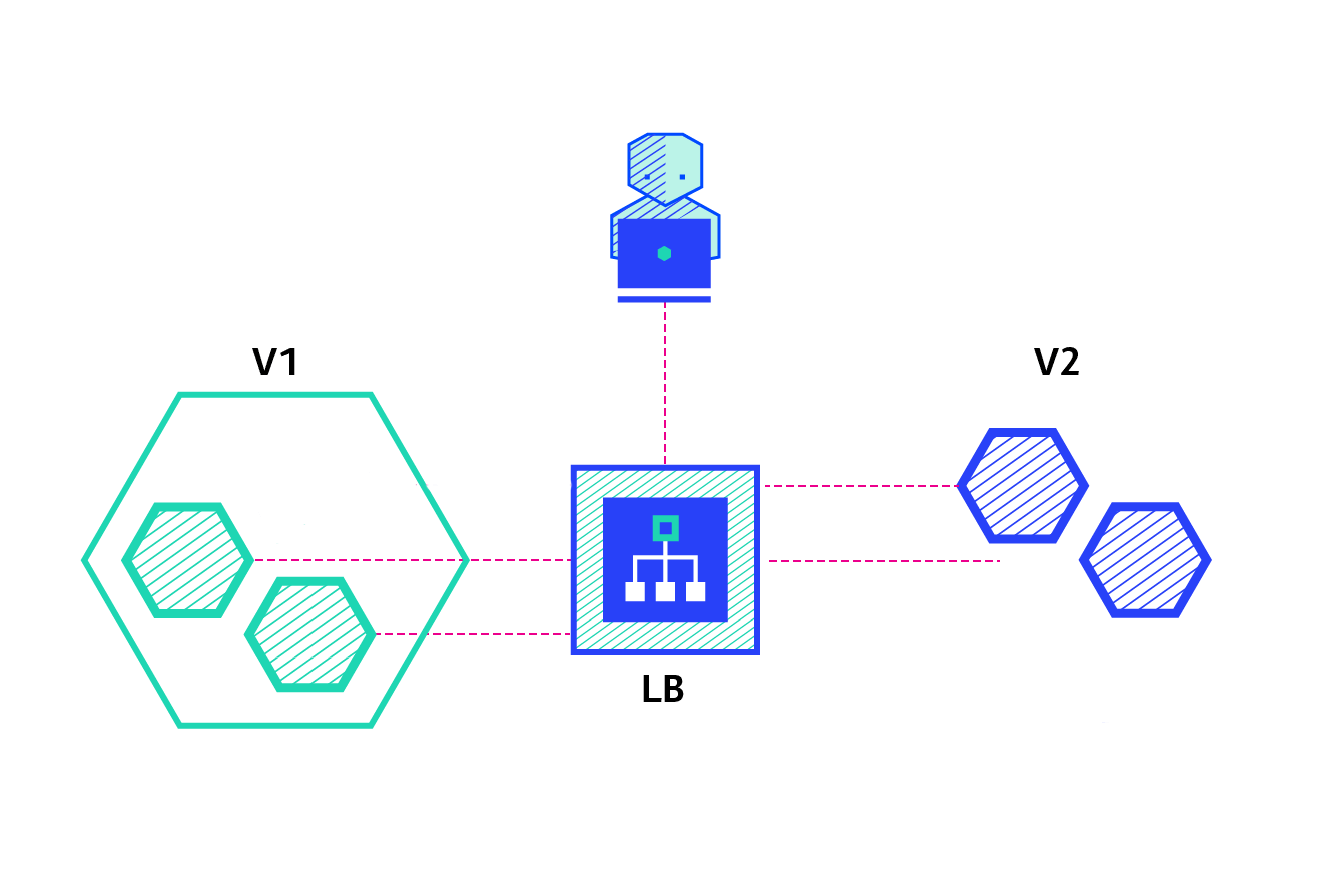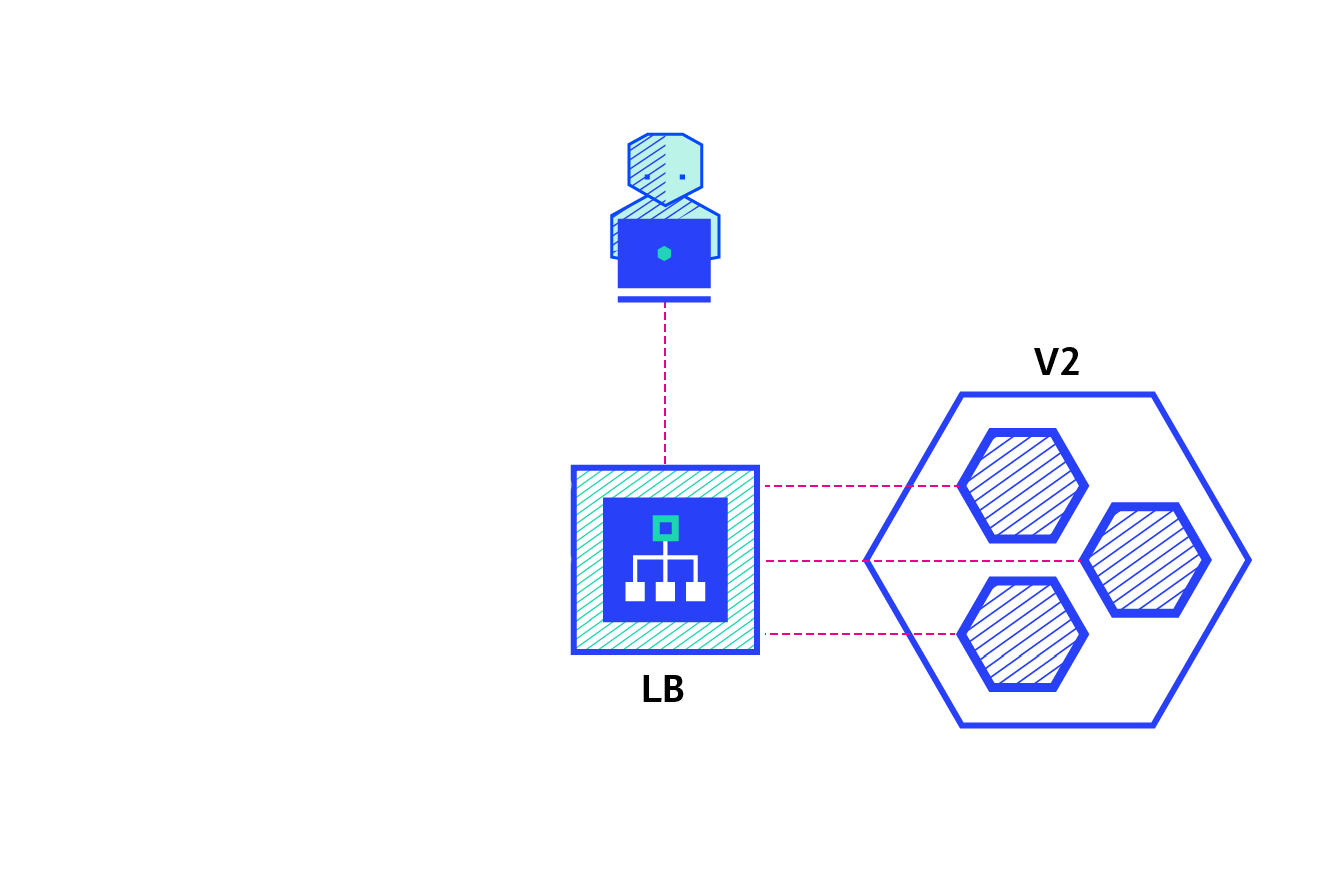
The animated image above illustrates how application updates can be rolled out for an already running application using the blue/green deployment method without having to take a system downtime. This is another invaluable feature of Kubernetes which allows applications to seamlessly roll out security updates and backwards compatible changes without much effort. If the changes are not backwards compatible, a manual blue/green deployment might need to be executed using a separate deployment definition.
This approach allows a rollout to be executed for updating a container image using a simple CLI command:
Once a rollout is executed, the status of the rollout process can be checked as follows:
Using the same CLI command kubectl set image deployment an update can be rolled back to a previous state.
Autoscaling

Figure 10: Kubernetes Pod Autoscaling Model
Kubernetes allows pods to be manually scaled either using ReplicaSets or Deployments. The following CLI command can be used for this purpose:
As shown in the above figure this functionality can be extended by adding another resource called Horizontal Pod Autoscaler (HPA) against a deployment for dynamically scaling the pods based on their actual resource usage. The HPA will monitor the resource usage of each pod via the resource metrics API and inform the deployment to change the replica count of the ReplicaSet accordingly. Kubernetes uses an upscale delay and a downscale delay for avoiding thrashing which could occur due to frequent resource usage fluctuations in some situations. Currently, HPA only provides support for scaling based on CPU usage. If needed custom metrics can also be plugged in via the Custom Metrics API depending on the nature of the application.
Package Management


Figure 11: Helm and Kubeapps Hub
The Kubernetes community initiated a separate project for implementing a package manager for Kubernetes called Helm. This allows Kubernetes resources such as deployments, services, config maps, ingresses, etc to be templated and packaged using a resource called chart and allows them to be configured at the installation time using input parameters. More importantly, it allows existing charts to be reused when implementing installation packages using dependencies. Helm repositories can be hosted in public and private cloud environments for managing application charts. Helm provides a CLI for installing applications from a given Helm repository into a selected Kubernetes environment.
A wide range of stable Helm charts for well-known software applications can be found in its Github repository and also in the central Helm server: Kubeapps Hub.
Conclusion
Kubernetes has been designed with over a decade of experience in running containerized applications at scale at Google. It has been already adopted by the largest public cloud vendors, and technology providers and is currently being embraced by most of the software vendors and enterprises as this article is written. It has even led to the inception of the Cloud Native Computing Foundation (CNCF) in the year 2015, was the first project to graduate under CNCF, and started streamlining the container ecosystem together with other container-related projects such as CNI, Containers, Envoy, Fluentd, gRPC, Jagger, Linkerd, Prometheus, RKT and Vitess. The key reasons for its popularity and to be endorsed at such a level might be its flawless design, collaborations with industry leaders, making it open-source, and always being open to ideas and contributions.
References
[1] What is Kubernetes: https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/
[2] Borg, Omega and Kubernetes: https://ai.google/research/pubs/pub44843
[3] Kubernetes Components: https://kubernetes.io/docs/concepts/overview/components/
[4] Kubernetes Services: https://kubernetes.io/docs/concepts/services-networking/service/
[5] IPVS (IP Virtual Server) http://www.linuxvirtualserver.org/software/ipvs.html
[6] Introduction of IPVS Proxy Mode: https://github.com/kubernetes/kubernetes/issues/44063
[7] Kubernetes Persistent Volumes: https://kubernetes.io/docs/concepts/storage/persistent-volumes/
[8] Kubernetes Configuration Best Practices: https://kubernetes.io/docs/concepts/configuration/overview/
[9] Customer Resources & Custom Controllers: https://kubernetes.io/docs/concepts/api-extension/custom-resources/
[10] Understanding Vitess: https://vitess.io/overview/
[11] Skaffold, CI/CD for Kubernetes: https://github.com/GoogleContainerTools/skaffold
[12] Kaniko, Build Container Images in Kubernetes: https://github.com/GoogleContainerTools/kaniko
[13] Apache Spark 2.3 with Native Kubernetes Support https://kubernetes.io/blog/2018/03/apache-spark-23-with-native-kubernetes/
[14] Deploying Apache Kafka using StatefulSets: https://github.com/kubernetes/contrib/tree/master/statefulsets/kafka
[15] Deploying Apache Zookeeper using StatefulSets: https://github.com/kubernetes/contrib/tree/master/statefulsets/zookeeper
Last updated
Was this helpful?